Features I want in an IDE
In this post, I break down the features I want in an IDE. I introduce seven categories of IDE features, describe their associated trade-offs and summarize my personal preferences.
Import project
The first thing you do with an IDE is boring but critical: import an existing project or generate a new project from a template. During import, the IDE learns about the modules of a build, dependencies and other configuration data. Failing to import a project is not fun because IDE features stop working. For example, if the IDE does not know the dependencies of a project there will be many spurious squiggles about unresolved identifiers.
The key objective for importing projects is ease of use. A beginner that has never written code before should be able to open an IDE and import a project. Importing a project should not be a complex multi-stage process. A complex setup makes users give up on using an IDE and at that point it won’t matter which advanced features the IDE supports.
Importing a project should
- require as few manual steps from the user as possible. Ideally, the user opens a directory in the editor, a popup window appears asking to import the project, user clicks “OK” and everything Just Works™️.
- be reasonably fast. It’s fine if a project import takes 5-10 seconds but if it takes minutes you’re sitting there idle not getting any work done.
- pick up new build changes. For example, when a new dependency is added to the build the IDE should notify the user asking to re-import the build.
Diagnostics
Diagnostics are one of the most basic but also difficult-to-support features in an IDE. Diagnostics are the red squiggles that appear under code to indicate a programming error.

In statically typed languages like Scala, squiggles are particularly useful but even dynamic languages benefit from catching syntax errors like unclosed quotes and mismatching parentheses.
For diagnostics, there’s a fine art in balancing interactivity with false negatives and positives. On one hand, you want programming errors to be displayed as fast as possible in the editor as you type. On the other hand, you don’t want to be distracted by spurious squiggles as you are in the process of writing an incomplete program.
How many false negatives and positives do we tolerate at which given latency? I think this is an interesting question and the answer may differ between individuals. Personally, I would prefer less noise at the cost of higher latency. What is a tolerable latency, however? For small projects, I would be happy write my program in peace, save my file and wait until sbt completes incremental compilation to populate my editor with build errors. For large projects however, incremental compilation can take dozens of seconds or even minutes. Is it productive to wait 20 seconds to catch a small typo? I’m not sure.
Diagnostics have a lower tolerance for false positives than false negatives. Concretely, I believe it’s better to have no diagnostics than false diagnostics. False diagnostics can be attributed to a misconfigured project, buggy re-implementations of language semantics or inconsistent state between the language server and editor buffer.
In essence, diagnostics should
- avoid false positives. Invalid programs should rather have no squiggles instead of spurious squiggles.
- have low latency. Ideally diagnostics should appear instantly (<100ms), it might be fine if diagnostics take a second or two to appear as long as they’re correct but if it takes >5 seconds to report diagnostics they become unusable.
Completions
Completions are suggestions for what program snippets can be typed next from the cursor.
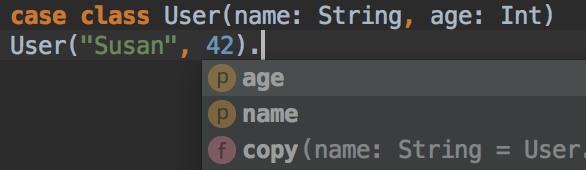
Completions are great for productivity when learning a new library because the editor is able to help you interactively explore the library interfaces.
There are primarily two kinds of completions: scope lookup and member lookups. Scope lookups are completion suggestions for identifiers that are available in scope at the cursor location. Member lookups are completion suggestions for methods and fields of a given type.
object Program {
Vect/*cursor*/ // Scope lookup: scala.collection.immutable.Vector
Vector.emp/*cursor*/ // Member lookup: .empty
}Additionally, completions can optionally include refactoring steps that should be applied once a completion item is selected.
// before
new Runna/*cursor*/
// after
new Runnable {
def run(): Unit = /*cursor*/
}
// before
File/*cursor*/
// after
import java.nio.file.Files
Files./*cursor/Completions have a lower tolerance for latency than diagnostics. It’s fine if a squiggle takes 1-2 seconds to appear but completions run on every keystroke. An acceptable latency for completions is closer to ~200-500ms. Thankfully however, completion suggestions do not always have to be perfect.
Completions have a higher tolerance for false positives/negatives than diagnostics. This may be controversial. Editors like Sublime Text and Vim provide completions without a compiler by simply suggesting identifiers from the open buffers. For many people, the speed of completion suggestions outweighs the quality of the suggestions. I am not implying completions get a free pass on correctness. The main point is that completions can afford more slack on correctness than diagnostics.
Unlike diagnostics, completions have a higher tolerance for false positives. Concretely, it is better to include partially incorrect suggestions than no suggestions. Sure, bogus completion suggestions that produce program errors are annoying. However, program errors will get caught by the compiler. Not discovering a method that solves your problem because completions are too conservative is worse.
In summary, completions
- are particularly sensitive to latency. Completions should ideally respond in <200ms, and they quickly become unusable if they take >1s to run on every keystroke.
- can afford more slack on correctness. Unlike diagnostics, spurious completion suggestions are not as bad as spurious squiggles.
Navigation
Navigation is the ability to browse sources with smart understanding of the code structure. It includes common features like goto definition and find references but also more advanced browsing capabilities such as goto implementations and overrides.
Locations of source code can roughly be split between project source files and external dependency source files. When jumping between sources, it matters which kind of location is being jumped from:
- Project -> Project
- Project -> Dependencies
- Dependencies -> Dependencies
Dependencies can further be broken down by language. In Scala, it’s common to depend on Java libraries and sometimes dependencies do not publish source files, in which case all you have is classfiles.
- Scala -> Scala
- Scala -> Java
- Scala -> Classfile
- Java -> Scala
- Java -> Java
- Java -> Classfile
- Classfile -> Scala
- Classfile -> Java
- Classfile -> Classfile
IDEs like the IntelliJ Scala plugin support the full matrix, which is useful when working in a hybrid codebase.
Building an index to support low latency navigation is compute and memory intensive. Typically, an IDE triggers indexing right after importing a project. The total time it takes to index a project and the memory consumption of the indexing process are important UX factors. Additionally, indexing needs to be incremental such that small changes to the codebase do not require a full re-index.
Balancing correctness with intuitiveness is a challenging problem in navigation. Navigation sometimes needs to be slightly fuzzy in order to support browsing invalid programs. Imagine the following scenario
// v1
def add(a: Int, b: Int): Int = a + b
add(1, 2)
// v2
def add(a: Int, b: Int, c: Int): Int = a + b + c
add(1, 2) // error: missing argument `c: Int`While refactoring in v2, you would expect goto definition in add(1, 2) to
work. Strictly speaking, there is no definition for add because the signature
has changed. However, because add(1, 2) references the old v1 def add goto
definition should jump to the new v2 def add.
Code navigation
- is not all or nothing. There’s a big matrix of features depending on project/dependency sources and Java/Scala/Classfile sources that can optionally be supported or not.
- is compute and memory intensive. An IDE becomes unusable if indexing is slow for large projects or too resource demanding for low-powered hardware.
- indexing should prioritize write performance over read performance. The number of read operations (goto, find references) are dwarfed by the number of write operations (index all project and dependency sources).
- needs to balance fuzzy-ness and correctness to support browsing partially incorrect programs without jumping to bogus locations.
Refactoring
Refactoring loosely means “tools that automatically fix problems in source code”. Popular refactorings include rename variable, organize imports and move class but for any given language there can be several hundreds of custom refactorings available. IDE refactorings roughly split between being on-demand or passive.
An on-demand refactoring is triggered by the user, for example rename variable. On-demand refactorings avoid repeating repetitive tasks enabling the user to develop at a higher level of abstraction.
A passive refactoring is recommended by the IDE to the user, regardless if the user knows beforehand about the refactoring or not. Passive refactorings are great at teaching developers best practices that would otherwise need to be learned through mentorship, training or code review. It is important to enable the user to learn why the refactoring fixes a problem and how to fix it.
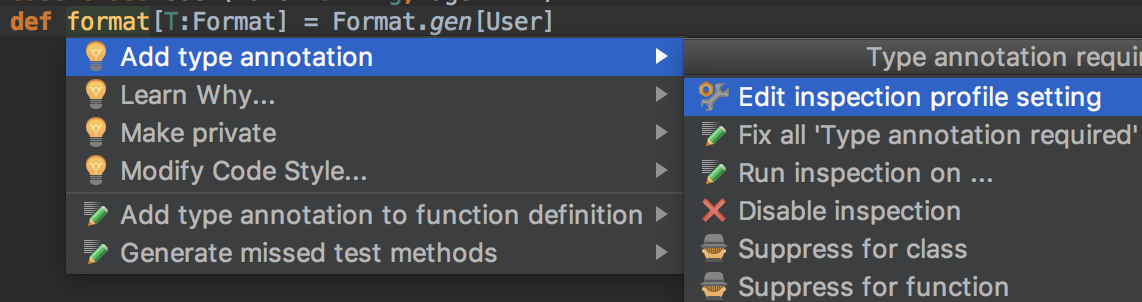
It is important to distinguish between batch-mode refactoring and interactive-mode refactoring. Tools like Scalafix have command line interfaces that enable batch-mode refactoring. Batch-mode refactoring allows the user to run multiple refactoring steps together in one go on a large number of files. In an interactive-mode, the user has fine grained control to apply individual refactoring steps on individual locations in a single source file. Passive refactorings are only possible in interactive-mode.
In a nutshell, refactorings
- can be on-demand or passive. On-demand refactorings are great to avoid repetitive tasks and passive refactorings are great for learning best practices.
- run in either interactive-mode or batch-mode. Batch-mode refactoring is great for enforcing best practices in a CI environment while interactive-mode refactorings are a great fit for IDEs.
Test and run
Test and run is the ability to execute programs directly from the IDE.
Typically, test and run is executed in batch-mode through a console interface of
a build tool. An IDE can provide a graphical interface through “Run” buttons
next to unit tests and main entrypoints. I personally don’t use this feature
because I prefer console interfaces. However, I believe test and run are widely
used IDE features and merit inclusion in discussions on what constitutes an IDE.
- Many users prefer to run programs and execute tests from the IDE instead of through a console interface.
Debugging
Debugging is the ability to attach to a running process of an application and
interactively step through the execution of the program inside the IDE. By
definition, debuggers do not run in batch-mode. I personally use pprint to
debug because my applications typically start up fast. However, I once used a
debugger when I was developing an IntelliJ plugin because startup was super slow
and I didn’t understand what was happening at runtime. It’s undeniable that
debuggers are popular and I suspect many consider debugging essential
functionality of an IDE.
- Debugging is great if your applications are slow to start, for example doing mobile app development. Many users expect IDEs to have baked-in debugging support.
Conclusion
Here’s what ended up on my personal wish-list for an awesome IDE:
- Import project: Critical. Should require as few steps as possible. If importing a project is too complex I can’t use the IDE.
- Diagnostics: Important. One of the most basic but difficult-to-support features of an IDE. Balancing latency and spurious squiggles is a big challenge.
- Completions: Important. Low latency is extra important because completions run on every keystroke.
- Navigation: Important. Building navigation indices should not consume all compute and memory resources.
- Refactoring: Nice-to-have. On-demand refactorings are great to avoid repetitive tasks and passive refactoring suggestions are great to learn about coding best practices.
- Test and run: Not important, I’m happy to use batch-mode console interfaces instead of clicking on “Run” buttons in the IDE.
- Debugging: Not important, I use
printlndebugging. If my applications were slower to start I might reconsider and want my IDE to support debugging.
How does your dream IDE look like? Share your thoughts on Twitter.